
2024-12-05 14:45:53.AIbase.
Byte's New Code Model Evaluation Benchmark 'FullStack Bench'

2024-10-09 15:51:44.AIbase.
AI Video Generation Model Evaluation Report: Minimax Text Control is the Strongest, Ling 1.5 Can Master “Water Pouring”

2024-09-29 15:33:05.AIbase.
Salesforce AI Launches New Large Language Model Evaluation Family SFR-Judge Based on Llama3

2024-08-13 08:11:01.AIbase.
The Compass Arena, a Large Model Evaluation Platform, Adds a Multi-Modal Large Model Competition Section

2024-08-07 14:14:43.AIbase.
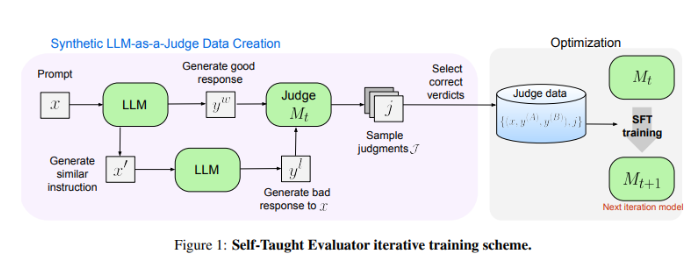
Meta Launches 'Self-Taught Evaluator': NLP Model Evaluation Without Human Annotation, Outperforming Common LLMs Like GPT-4
2024-03-07 03:52:56.AIbase.
AI Model Evaluation Company Points Out Serious Infringement Issues with GPT-4, Microsoft Engineers Express Concerns Over Image Generation Features
2023-11-30 09:52:30.AIbase.
Amazon AWS Launches Human Benchmark Testing Team to Improve AI Model Evaluation
2023-11-29 09:08:23.AIbase.
"Baimao Battle" Family's First, When Will Cheating in Large Model 'Scoring' Stop?
2023-11-02 15:21:41.AIbase.
Ant Group Releases Benchmark for Large Model Evaluation in the DevOps Field
2023-09-25 09:54:21.AIbase.
Investigation into the Chaos of Large Model Evaluation: Parameter Scale Does Not Represent Everything
2023-08-29 10:09:08.AIbase.
August Rankings! SuperCLUE Releases Latest Rankings for Chinese Large Model Evaluation Benchmark
2023-08-18 10:04:45.AIbase.