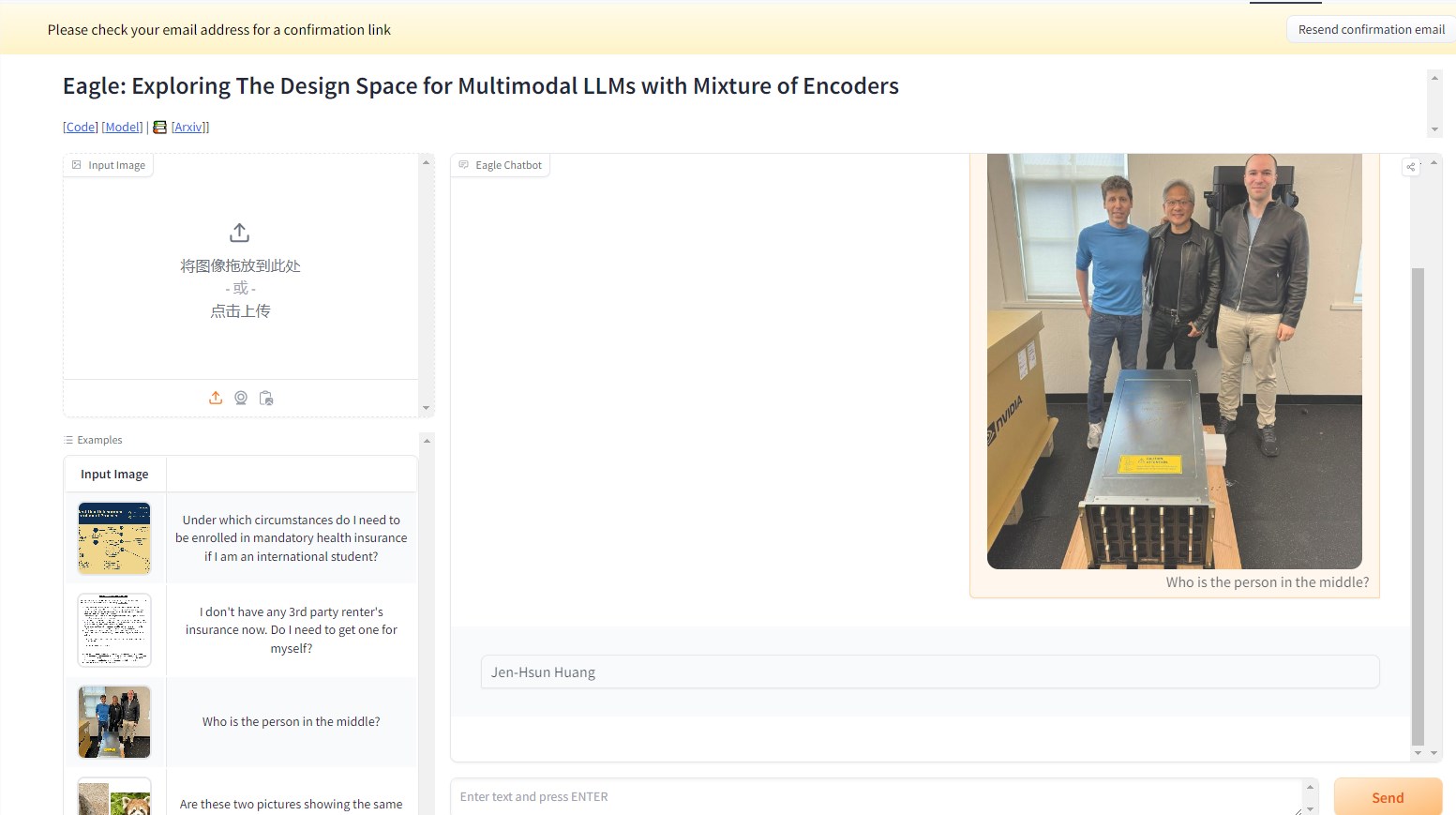
El 2 de septiembre, Tongyi Qianwen anunció la publicación de código abierto de su modelo de lenguaje visual de segunda generación, Qwen2-VL, y lanzó en la plataforma Bailian de Alibaba Cloud las API de dos modelos de diferentes tamaños (2B y 7B) y sus versiones cuantificadas, para que los usuarios puedan llamarlos directamente.
El modelo Qwen2-VL ha logrado una mejora integral del rendimiento en varios aspectos. Puede comprender imágenes de diferentes resoluciones y relaciones de aspecto, y ha establecido un rendimiento líder a nivel mundial en pruebas de referencia como DocVQA, RealWorldQA y MTVQA. Además, este modelo puede comprender videos largos de más de 20 minutos y admite aplicaciones como preguntas y respuestas, conversaciones y creación de contenido basados en video. Qwen2-VL también posee una potente capacidad de agente de inteligencia visual, pudiendo operar de forma autónoma teléfonos móviles y robots, realizando inferencias y toma de decisiones complejas.
Este modelo puede comprender texto multilingüe en imágenes y videos, incluyendo chino, inglés, la mayoría de los idiomas europeos, japonés, coreano, árabe y vietnamita. El equipo de Tongyi Qianwen evaluó las capacidades del modelo desde seis aspectos: problemas universitarios integrales, capacidad matemática, comprensión de imágenes de texto multilingüe en documentos y tablas, preguntas y respuestas en escenarios generales, comprensión de video y capacidad de agente.

Qwen2-VL-72B, como modelo insignia, ha alcanzado el rendimiento óptimo en la mayoría de los indicadores. Qwen2-VL-7B, con su tamaño de parámetros económico, ha logrado un rendimiento altamente competitivo, mientras que Qwen2-VL-2B admite una amplia gama de aplicaciones para dispositivos móviles y posee una capacidad completa de comprensión de imágenes y videos multilingües.
En cuanto a la arquitectura del modelo, Qwen2-VL continúa con la estructura en serie de ViT más Qwen2. Los tres modelos de diferentes tamaños utilizan un ViT de 600M, admitiendo la entrada unificada de imágenes y videos. Para mejorar la percepción de la información visual y la capacidad de comprensión de video del modelo, el equipo realizó actualizaciones en la arquitectura, incluyendo la implementación de soporte completo para resolución dinámica nativa y el uso del método de incrustación de posición rotacional multimodal (M-ROPE).
La plataforma Bailian de Alibaba Cloud proporciona la API de Qwen2-VL-72B, que los usuarios pueden llamar directamente. Simultáneamente, el código abierto de Qwen2-VL-2B y Qwen2-VL-7B ya está integrado en Hugging Face Transformers, vLLM y otros frameworks de terceros, permitiendo a los desarrolladores descargar y utilizar el modelo a través de estas plataformas.
Plataforma Bailian de Alibaba Cloud:
https://help.aliyun.com/zh/model-studio/developer-reference/qwen-vl-api
GitHub:
https://github.com/QwenLM/Qwen2-VL
HuggingFace:
https://huggingface.co/collections/Qwen/qwen2-vl-66cee7455501d7126940800d
魔搭ModelScope:
https://modelscope.cn/organization/qwen?tab=model
Experiencia del modelo:
https://huggingface.co/spaces/Qwen/Qwen2-VL